![]()
Manufacturers are constantly introducing new products. Although you know which new products your own company is introducing and when, it is also important for you to keep informed about your competitors’ activity. Depending on the resources at your company, you can do anything from annual analysis to on-going monthly (or even weekly) tracking.
This is the first in a series of posts that show how you can use your IRI or Nielsen POS database to conduct an annual analysis of all the new items introduced in your category.
- Part I: How to Identify New Items ⇐ this post
- Part II: What to Include in An Annual New Item Summary
- Part III: How to Tell The “New Item Story” for Your Category
Was it here last year? Look at Distribution
Another way of asking “which items are new?” is “which items were already here last year?” The simplest way to answer either of these questions is to look at distribution for all items in the category in the current period compared to the same period in the prior year. If an item has distribution greater than 0 in both years, then it is not new in the current year. See this post for more on distribution.
Since the focus of this post is identifying any new items in the category, we will be selecting the largest available Total US market. (See this post on Total US markets.) If your business is not national and more regional, you could do this for a specific region, market or groups of markets. If you are calling on a particular retail customer, you may want to do this for that customer to see what new items they have taken on in the past year.
Run a query (IRI or Nielsen) that contains the following, making sure to have the Products in the rows and the Facts in the columns:

* It is best to use current month. Using the most recent week will understate the distribution for most items since distribution is based on where an item actually scans and not on where it is stocked. Using a 52-week value will give you the average distribution across all 52 weeks, including all the zero weeks before the item was out there, not the most recent.
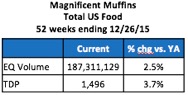
Your report will look something like this:

(Note that this example only shows 20 items in the category. Your category may have hundreds or thousands of items!)
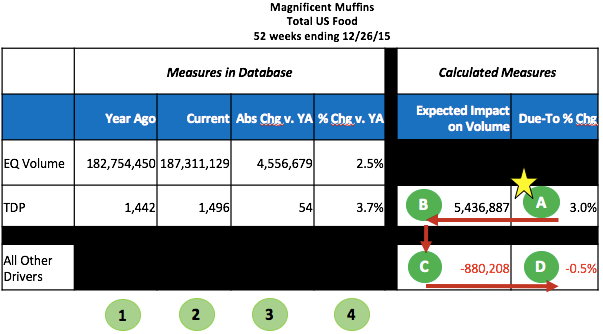
Looking at this, it’s pretty obvious that items M, S and T are new since their change in distribution is the same as their current distribution. Therefore, they were not in-market during this same period last year. If you sort the items in descending order of change in distribution, you can see that items F and G also appear to be new:

Obviously items M, S and T are the most interesting, since they are in relatively high distribution. Even though items F and G are also new, you may or may not want to do further analysis on them since they are in such few stores. You could add another column to this data in Excel that indicates if the current distribution meets some minimum threshold (like 5 or 10% ACV) and also sort on that to more easily focus on new items with significant distribution. But what about item C? The change in distribution is almost the same as the distribution itself (50 vs. 53). You may want to still consider this as a new item in the current year, even though it’s introduction began in the prior year. One more column in the file could calculate the change divided by current distribution so you can more easily find items similar to UPC C. Doing that would show 1.0 for all truly new items and 0.94 for item C (50/53) but only 0.47 (7/15) for item K and 0.12 (7/60) for item N.
Another thing to watch out for when identifying new items are special packs (also called in-and-out items) that tend to be in-market for short periods of time – like bonus packs, bundle packs or pre-price. Although these may show up in this type of new item analysis, they are really just variations of existing items. You can usually recognize such items by certain abbreviations in the product description (like +1.5OZ or 99¢ PP). It is important to be aware of such items but they are not really indicative of true innovation happening in the category.
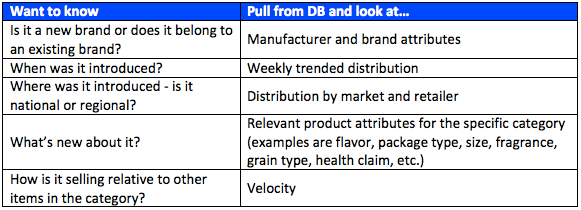
Once you have identified the most important new items, you’ll have some natural follow-up questions like:
- Are the new items line extensions of existing brands or are they totally new brands in the category?
- Were the new items introduced just this month or several months ago? We can’t tell just from this data. Maybe that’s why distribution is so low for items F and G – they could have been introduced last week while items M, S and T have been around for almost a year.
- Are the new items regional or national?
My next post on New Items will focus on these and other things you’ll want to know about the new items.
Do you have a different way to identify new items? How often are you tracking competitive new items? We’d love to hear how you think about this. If you have other questions about new items in the IRI/Nielsen data, please contact us for a free 30-minute consultation or leave a Comment for this post.
Subscribe to CPG Data Tip Sheet to get future posts delivered to your email in-box. We publish articles every few weeks. We will not share your email address with anyone.
The post What’s New, Part I: How to Identify New Items in Your Category appeared first on CPG Data Tip Sheet. Copyright © 2014 CPG Data Insights.
 For my last couple of posts, I’ve been talking about the
For my last couple of posts, I’ve been talking about the 
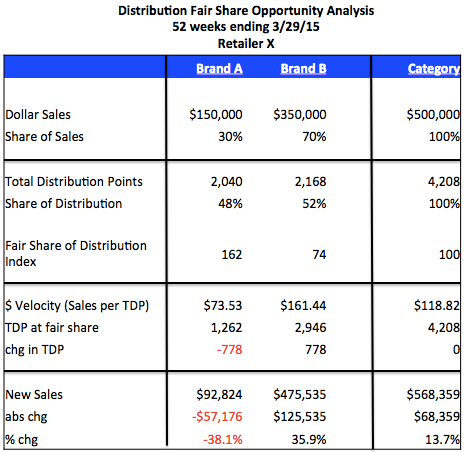
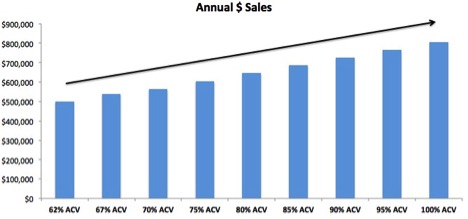

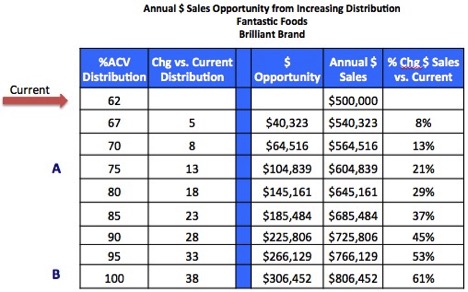

 Earlier this year, we received a frustrated email from a reader. He wrote: “Once and for all, I would like to know exactly what ACV is. You hear several definitions depending on the site you visit. Then I would like to know how to calculate it, what it tells me, and why suppliers should care.” A great list of questions about an important CPG metric!
Earlier this year, we received a frustrated email from a reader. He wrote: “Once and for all, I would like to know exactly what ACV is. You hear several definitions depending on the site you visit. Then I would like to know how to calculate it, what it tells me, and why suppliers should care.” A great list of questions about an important CPG metric!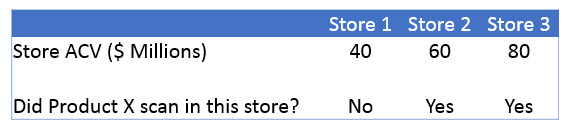
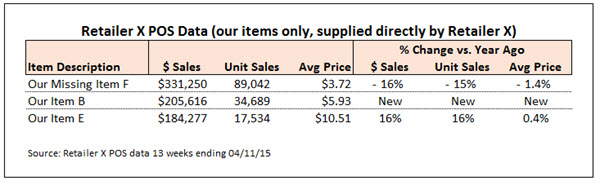
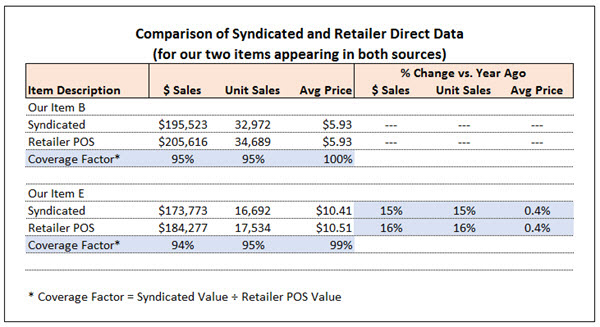
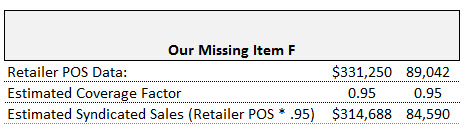
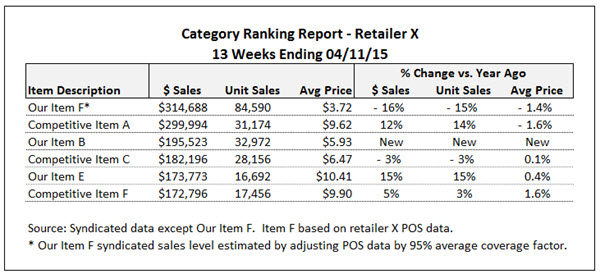
 One of the advantages of syndicated store data is that it provides you with the most comprehensive retail sales picture you can obtain from a single source. But sometimes you can get greater insight and formulate more powerful arguments by enhancing your syndicated data with information from other sources.
One of the advantages of syndicated store data is that it provides you with the most comprehensive retail sales picture you can obtain from a single source. But sometimes you can get greater insight and formulate more powerful arguments by enhancing your syndicated data with information from other sources.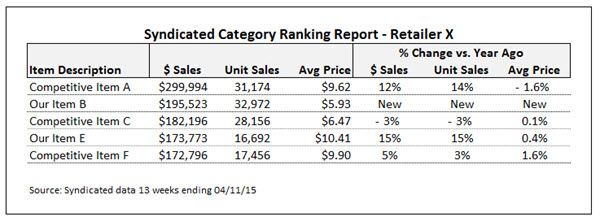
 Despite the promise of software vendors that their “methodologies extract meaningful and actionable insights from Big Data,” my experience is that no methodology can substitute for the human brain of an astute analyst. Great data analysts are a rare and valuable commodity. So what makes for a great one?
Despite the promise of software vendors that their “methodologies extract meaningful and actionable insights from Big Data,” my experience is that no methodology can substitute for the human brain of an astute analyst. Great data analysts are a rare and valuable commodity. So what makes for a great one? What are the three most important qualities of a great data analyst?
What are the three most important qualities of a great data analyst?



 In the CPG industry, syndicated retail sales data from vendors Nielsen, IRI and SPINS is everywhere. Users include retailers, brokers and distributors, direct sales and brand management teams, operations and supply chain forecasters, business journalists, and finance gurus! So if you’re in the CPG industry, you need to be syndicated data literate.
In the CPG industry, syndicated retail sales data from vendors Nielsen, IRI and SPINS is everywhere. Users include retailers, brokers and distributors, direct sales and brand management teams, operations and supply chain forecasters, business journalists, and finance gurus! So if you’re in the CPG industry, you need to be syndicated data literate. Last month, I started my list of the top 10 syndicated retail sales data terms and concepts. Syndicated data from vendors Nielsen, IRI and SPINS is prevalent in the consumer goods industry. No matter your function, you’ll benefit from syndicated data literacy.
Last month, I started my list of the top 10 syndicated retail sales data terms and concepts. Syndicated data from vendors Nielsen, IRI and SPINS is prevalent in the consumer goods industry. No matter your function, you’ll benefit from syndicated data literacy. 
 We’re delighted to have guest contributor Scott Sanders, senior consultant at Simon-Kucher & Partners, share his expertise with CPG Data Tip Sheet readers. Scott’s contact details can be found at the end of this article.
We’re delighted to have guest contributor Scott Sanders, senior consultant at Simon-Kucher & Partners, share his expertise with CPG Data Tip Sheet readers. Scott’s contact details can be found at the end of this article. Example of an interpretation: Above, much of the manufacturer’s profit is eaten up by discounts, shown as trade spending, which is used here largely to allow the retailer to discount from MSRP (manufacturer’s suggested retail price) to its ASP (average selling price).
Example of an interpretation: Above, much of the manufacturer’s profit is eaten up by discounts, shown as trade spending, which is used here largely to allow the retailer to discount from MSRP (manufacturer’s suggested retail price) to its ASP (average selling price).
 We ideally see that consumers receive a consistent value across sizes in the portfolio, with a discount as the volume in each package increases. We would want to see a smooth (or, at least, smooth-ish) line sloping from the high index to the low index.
We ideally see that consumers receive a consistent value across sizes in the portfolio, with a discount as the volume in each package increases. We would want to see a smooth (or, at least, smooth-ish) line sloping from the high index to the low index.
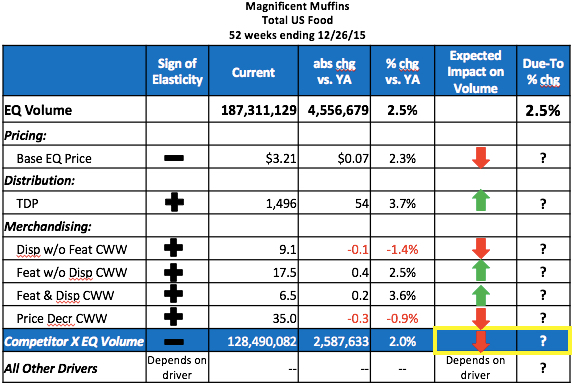
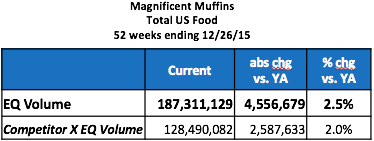

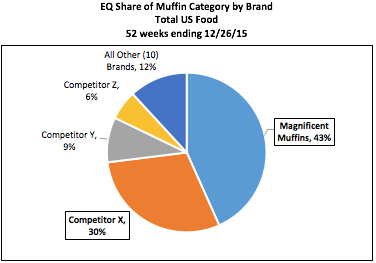
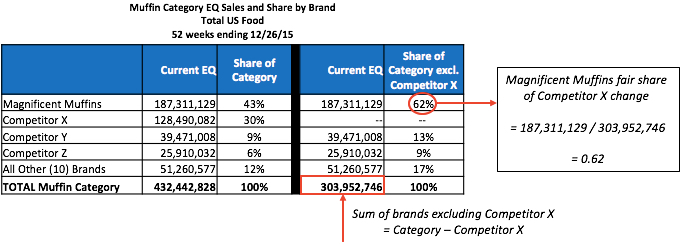
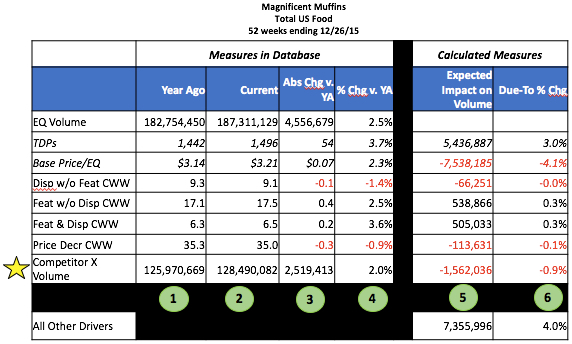
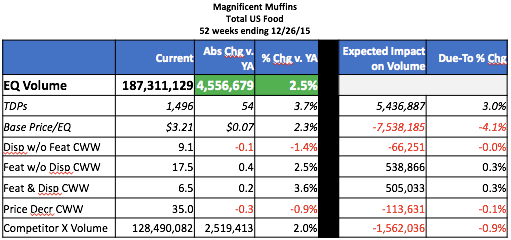


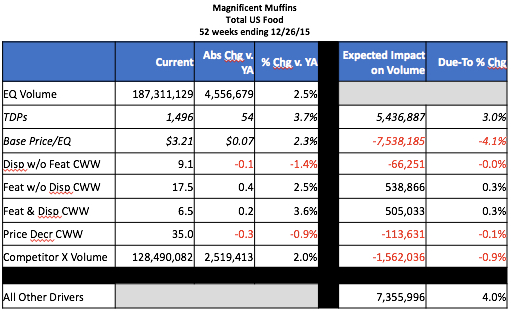
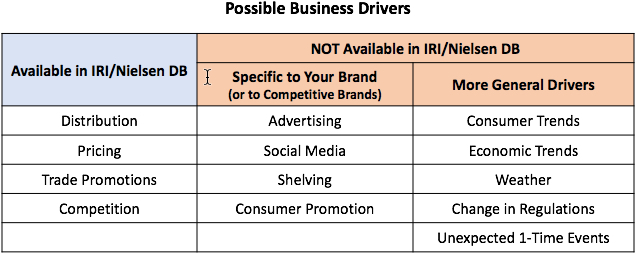
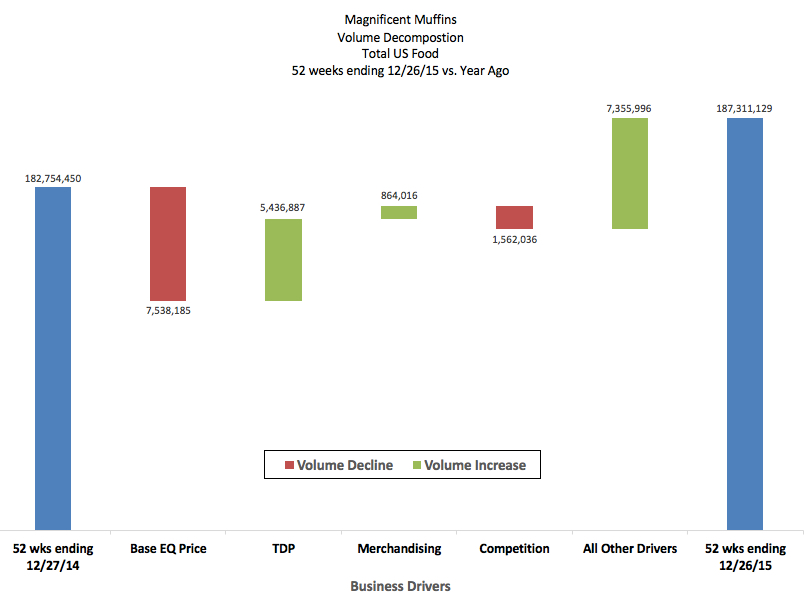
 TDP (a.k.a.
TDP (a.k.a. 

